Machine Learning: A Simple Neural Network
A simple neural network implementation in python with numpy
For the last few months I've been slowly getting my head around the concepts of machine learning, artificial intelligence and neural networks. The impact that machine learning could potentially have on everyday tasks and the way we develop and interact with applications is incredibly exciting; for that reason I been slowly trying to spend as much of my free time as possible trying to learn this big and complex field.
As part of that learning process I been get a better understanding of what neural networks are, how they work and what kind of applications they can be given, in this first blog post I'll start by creating a simple Neural network and in further post build up on this simple neural network.
What are neural networks?
Artificial Neural Networks(ANN) or simple referred as neural networks are at it simplest definition is a computational systems conformed of highly interconnected components which capture and represent complex input-output relationships. In essence ANN are a rough attempt to emulate the functionality of biological neural networks.
Typically neural networks are comprised by multiple layers of "neurons" or nodes, as well there are many variations and combinations of ANN like Convolutional Neural Networks(CNN) and Recurrent Neural Networks(RNN); in our case we are going to create the simplest example possible, a single layer, single neuron Neural network.
A simple Neural Network
Let's start by defining the problem our network will be trained to solve:
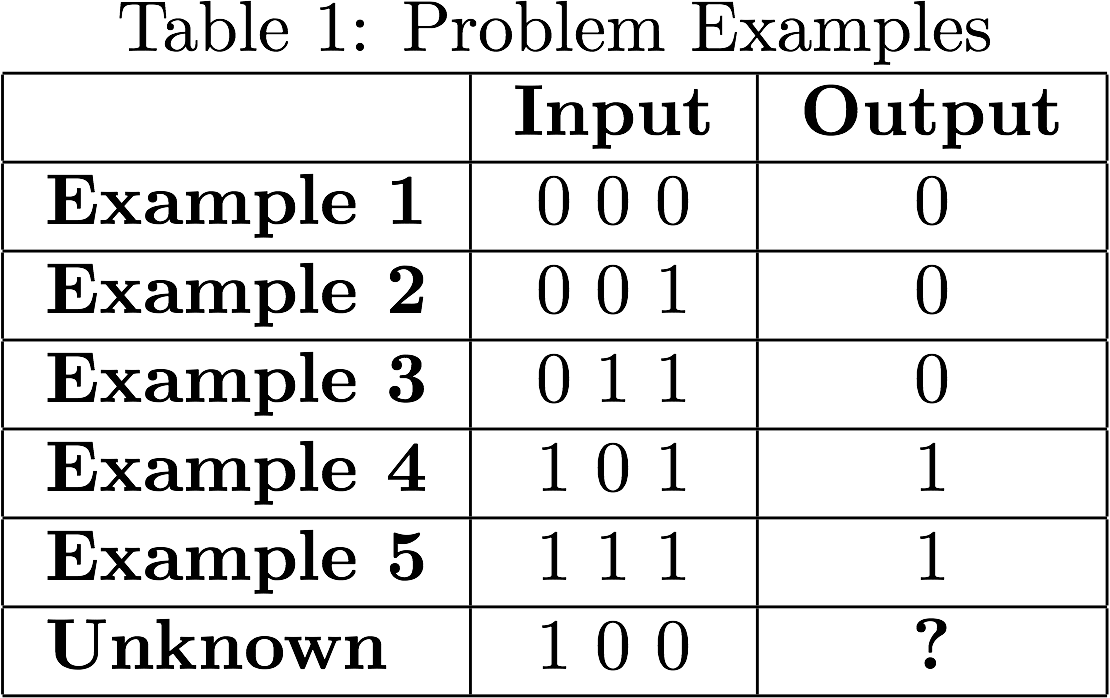
We are trying to find the value of the last example, know for anyone paying enough attention, the output value will match the value of the input left-most column; let's see if we can make our neural network answer the question correctly.
Based on the examples inputs and outputs our neuron will need to take 3 inputs and return a single output.
How does Training work?
We have a training dataset, so now is time to train our neuron based on the known examples, but how does this process work? are we really teaching a computer to think?
Well no, not really the process could be more accurately described as an educated guess by the computer. In order to train neuron we are going use a technique called backpropagation, which according to Wikipedia is:
Backpropagation, an abbreviation for "backward propagation of errors", is a common method of training artificial neural networks used in conjunction with an optimization method such as gradient descent. The method calculates the gradient of a loss function with respect to all the weights in the network. -- Wikipedia
Clear right?, yeah no worries I got stumped as this point as well; let's dig a little into another concept of our neural network in order to understand what's happening during the training a little better.
As we mentioned before our neuron will take three inputs per example, each of this inputs is connected to our neuron by a "synapse" the way training works is by assigning each input synapse a weight that can go from a positive to a negative number.
In our case we will be training against a know dataset, so the process will roughly look as follows:
- Load the training set from the known examples.
- Set random weights for each input.
- Pass the input and the weight to a mathematical formula to calculate the output.
- Calculate the error, that is to say the different between the neuron's output and the known value.
- Based on the error adjust the weights slightly.
- Rinse and repeat, 10,000 times
By doing this will eventually come to an optimal set of weights for our training set; assuming that our unknown examples follow the same patter then the neuron should be able to make an accurate prediction. This in a nutshell is what we call backpropagation.
The Math
Now, you might be wondering how the actual output values are calculated; in this case we are using a Sigmoid function to calculate the output values. Let's quickly take a look at the math involved.
A sigmoid function is a bounded differentiable real function that is defined for all real input values and has a positive derivative at each point. -- Wikipedia
I don't want to go to deep in the math of how and why this kind of logistic function is better suited for what we are currently trying to do, for now its enough to know that a sigmoid function will work for use case and it has an easy derivative to calculate.
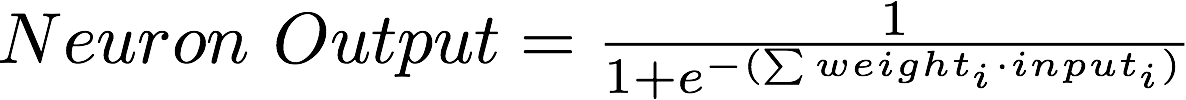
The plotted result of the above function will look like the following curve:

Keep in mind that this is not the only type of neuron, and depending on the kind of neural network and job we are giving it we might use other kinds of functions to calculated the output.
Adjusting the weights
The second part to this neuron code is to be able to adjust the synaptic weights during training, in order to do that we need to provide a second function that will calculate the adjustment.
In this case we will make use of another machine learning formula "Error Weighted Derivative" or delta rule.
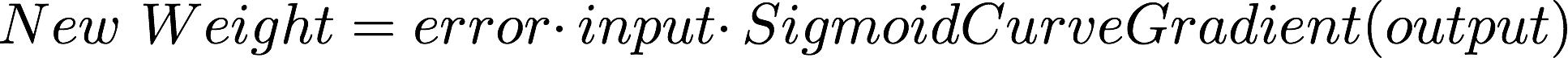
Or better represent by:
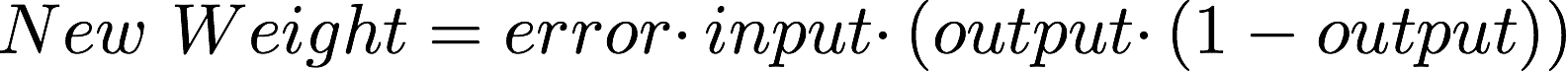
This formula will adjust the weight proportionally to the output of neuron; by using the original sigmoid curve as part of the calculation, we make sure that the more confident the neuron is the smaller the adjustment will be.
Show me the code
Ok enough math and theory, let's go ahead and write some python. First and foremost we will need to include the following methods from the numpy library:
- array: used to create matrices
- random: generates a random number
- exp: calculates the natural exponential
- dot: used to multiply matrices
Next we will need to define the training set inputs and outputs, for that we can split them into 2 separate matrices:
Following that we will need a variable to hold the unknown input:
As well we need to generate the set of weights for each one of our inputs:
The code above sets the seed for the random number generator, doing so will return the same random numbers between runs. Let's print the synapse_weights to see the results:
Which should generated something like the following:
[[-0.16595599]
[ 0.44064899]
[-0.99977125]]It doesn't matter how many times we run our example our initial weights will always be the same.
Now, what would happen if we where to run our neural network without training? What do you think would happen? Would be get an accurate result?
Let's find out:
Let's look at the last line we just added, take a few seconds to read the code. All that function is doing is translating our sigmoid function into code, which will always return a value between -1 or 1.
Go ahead and run the code above, you can expect to see something like the following output:
[ 0.45860596]And as you can see that value is not terrible accurate, I guess we kinda, coulda, maybe say the value is close to 0 but that won't do it, we are looking for a value as close as possible to either 1 or 0.
With that said the only remaining step is to train our ANN before actually calculating the output, and we will do that by running the sigmoid function 10,000 times and tweaking the weights on each iteration.
The code above will let us take a peak at the trained synapse weights, which look like the following in my case:
# Before training
[[-0.16595599]
[ 0.44064899]
[-0.99977125]]
# After training
[[ 9.67299303]
[-0.2078435 ]
[-4.62963669]]That's some difference, but will that result in any improvement? Let's find out by running the following and final snippet:
Resulting in;
[ 0.99993704]Bam! I would said that is a pretty accurate result. Experiment tweaking some of the values or trying to calculate a different example.
Conclusion
You made it to the end of the post!! Congratulations! This one was a long one and by no means a necessarily easy one to follow. However, keep in mind we are just scratching the surface, I skimmed on a lot of concepts and theory, the math alone could take several posts to start from scratch.